
It wasn’t Steve Jobs, but former Apple Computer CEO John Sculley, who in his book Odyssey: Pepsi to Apple, introduced us to the Knowledge Navigator, an astoundingly capable virtual assistant. Today, more than thirty years later, smart speakers are trying to implement at least some of the conversational concepts, envisioned in the Knowledge Navigator video, which premiered in 1987 at Educom.
According to Canalys, 75 million smart speakers will be sold worldwide in 2018. Amazon Echo and Google Home devices have a market share of about 30% each and more than 50% of all devices are sold in the US.
According to dashbot, 75% of those who own a smart speaker use it daily, with 57% using their device many times a day.
Obviously, a smart speaker is no Knowledge Navigator, at least not yet. Listening to music, asking for weather information, and setting a timer are the most popular use cases. It’s doubtful that consumers spent a significant amount of time and effort, evaluating competing experiences, but instead go with the platform they are already invested in. Even so, imagine a level playing field, how would one decide?
Voice first or voice only experiences don’t have a traditional (graphical) user interface. In this new environment of ambient-computing, neither form factor nor looks matter. All other things being equal, it’s how a user perceives a response that might eventually determine the success of a voice platform or that of a skill or application running on one of those platforms. Not only what, but equally how a virtual assistant says it, will determine success.
Likability becomes the ultimate differentiator in an otherwise un-differentiable experience.
Creating a likable experience doesn’t mean that a virtual assistant should aspire or pretend to be human. You also don’t need to hire novelists, poets, comedians, and fiction writers, trying their very hardest to build personality quirks into the most mundane or rote activities. Simply put it is about making a connection with the user.
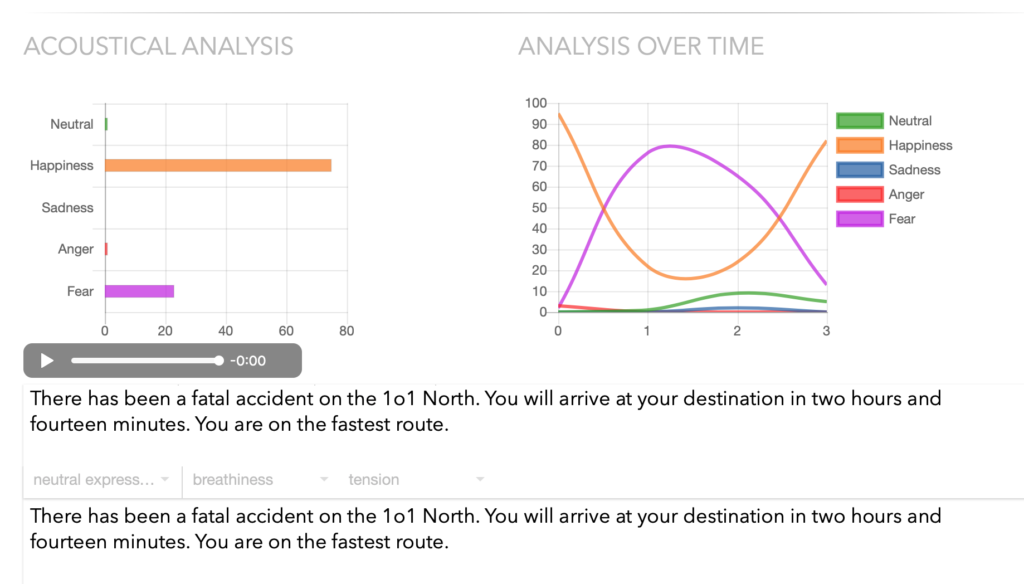
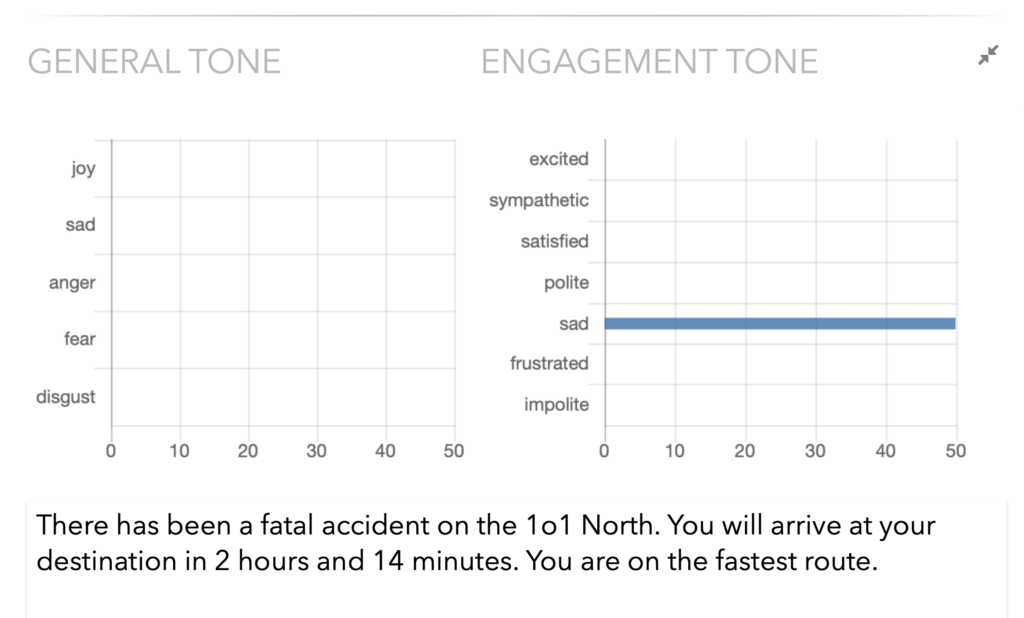
Currently, smart speakers are more like digital slaves, only allowed to speak when spoken to. Regardless, reading or hearing a kind response can be a delightful experience. But rather than being kind, it is important the intended attitude or sentiment comes across unambiguously. An example not to follow would be this response from a virtual assistant inside a maps app, announcing not with empathy but gleefully with obvious happiness in her voice:
“There has been a fatal accident on the 101 North. You will arrive at your destination in two hours and fourteen minutes. You are on the fastest route.”
Mistakes like that can easily be avoided, by matching the emotions and tones found in the text, with those recognizable in the voice.
Emotion Recognition in Voice
Paul Boersma, professor of Phonetic Sciences at the University of Amsterdam, (and author of the leading speech analysis software Praat) created a system that measures from voice input, whether the speaker sounds happy, sad, afraid, angry, or has a neutral state of mind. It can reach the performance level of a dedicated human listener, even if hearing a speaker’s voice for the first time.
While Boersma’s emotion recognizer was not created with speech synthesizers in mind, nothing prevents us from using it to evaluate synthesized speech.
Changing stress and intonation by varying prosodic parameters for pitch, pitch range, volume and speech rate, can change how emotion in synthesized speech is perceived. A pitch increase, for instance, could be used to inject emotions with high excitation (anger, fear, and happiness), while a pitch decrease, or a narrowing of the pitch range is an option for emotions with little excitation (sadness or boredom). We tend to say positive things faster while slowing down at negative information.
Speech Synthesis Markup Language (SSML)
SSML Version 1.1 is an W3C recommendation since September 2010, but there still isn’t a single synthesizer that has implemented the entire specification. Moreover, the results of the already implemented features vary. Still, SSML allows us to adjust the speech synthesis, for instance, permitting to control emphasis, pitch, pitch-range, speaking rate, and volume of the speech output.

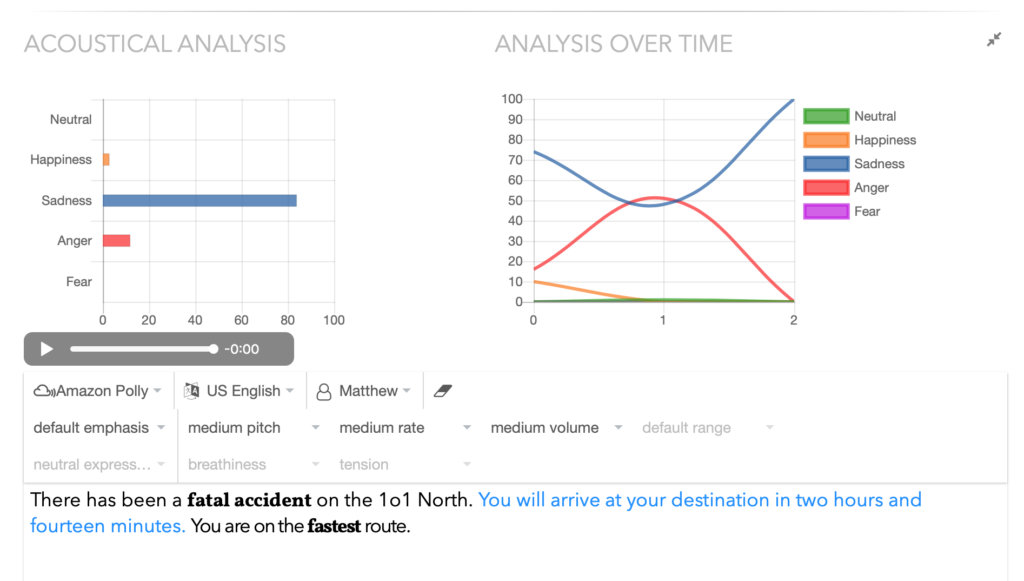
IBM extended SSML for its speech synthesizer, adding proprietary tags, allowing a more straightforward approach, targeting a whole sentence or phrase. Dubbed “Expressive SSML”, text can be wrapped into <express-as> tags and typed as ‘GoodNews’, ‘Apology’, or ‘Uncertainty’.
But long before diving into the cumbersome process of adjusting the perceivable emotion in synthesized speech, comes the task of finding the right tone in a text or script.
Emotions and Tones in Text
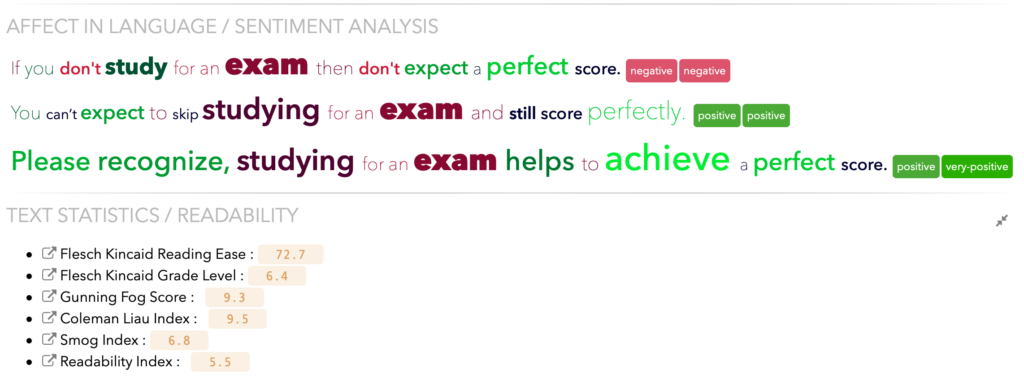
Before diving deeper into the sentiment of sentences, or the pleasantness, activation, and imagery of isolated words, let’s look at three sentences, all saying pretty much the same thing, but expressing a different attitude, maybe reflecting the attitude of the writer or speaker.
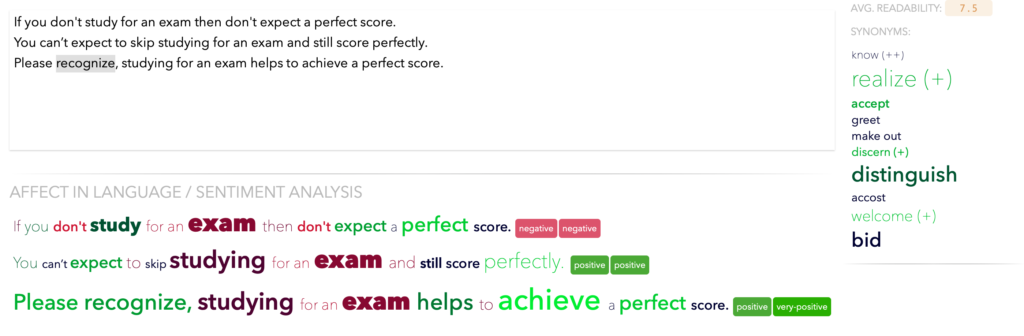
- If you don’t study for an exam, then don’t expect a perfect score.
- You can’t expect to skip studying for an exam and still score perfectly.
- Please recognize, studying for an exam helps to achieve a perfect score.
Which of these similar sentences is most likable? Which best expresses the emotion the author wishes to convey? We have developed tools to help with these questions.
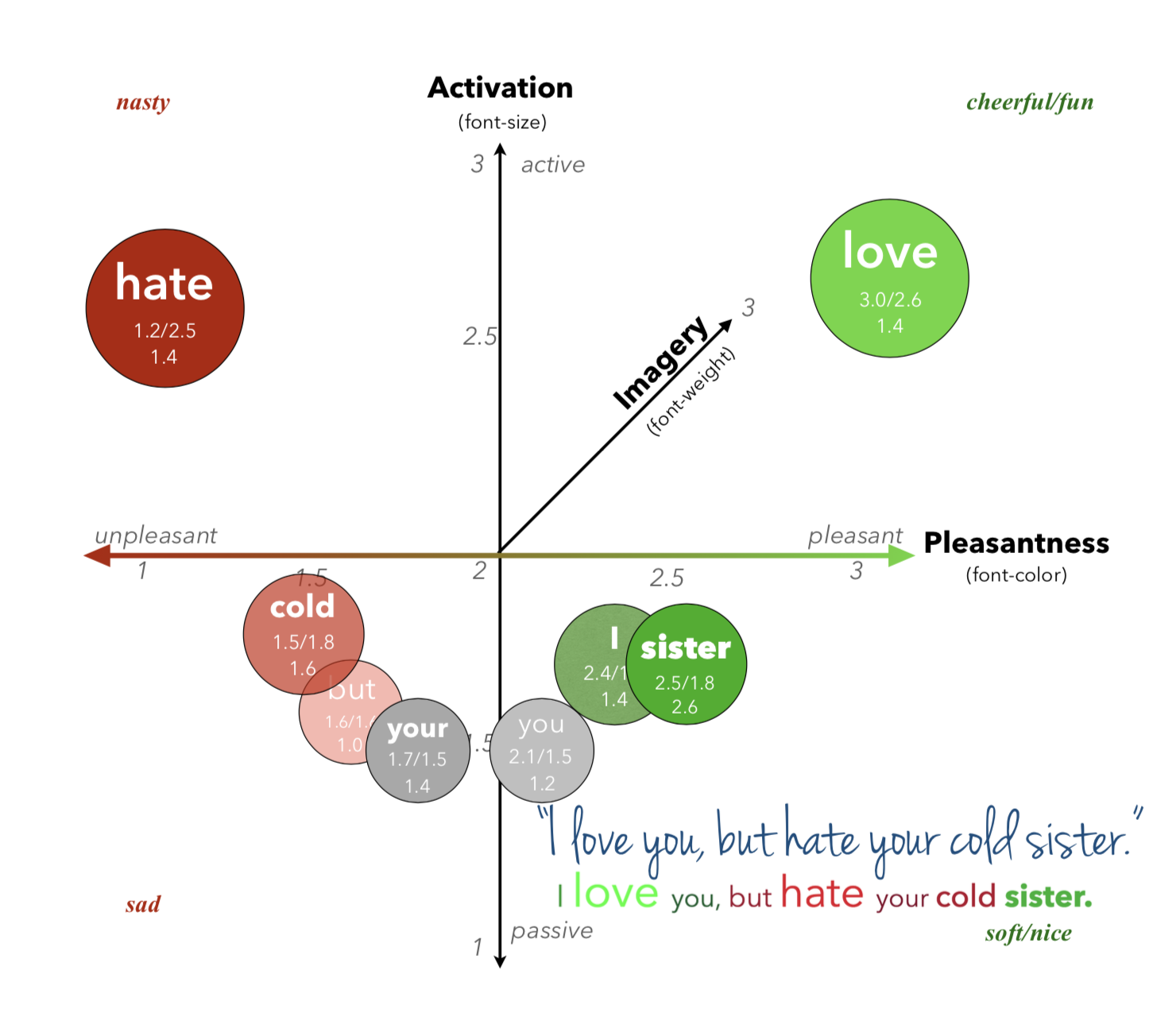
Visualizing pleasantness, activation, and imagery
Using Cynthia Whissell’s Revised Dictionary of Affect in Language, words are marked-up based on their pleasantness, activation, and imagery (ability to form a mental picture).
Green and red tones are used to visualize the pleasantness of a word. Very pleasant words are rendered in bright green and very unpleasant words are rendered in bright red, and everything in between.
The font-size is used to visualize the activation of a word. Very active words are shown in a large font size, passive words are rendered in a smaller font. Fun or cheerful words have high scores in both, pleasantness and activation. Sad words have low scores in pleasantness and activation. Nice or soft words have a high pleasantness, but a low activation. Nasty words have a low pleasantness, but a high activation.
Reading an engaging story can prompt vivid imagery of the described events and reported feelings of emotion. Research has confirmed this phenomenonand demonstrates that text-driven imagery prompts heightened autonomic and somatic reactions consistent with affective engagement.
Highly imaged words, effectively, making a story more memorable, are rendered with a bold font. Poorly imaged words are rendered with a thin/light font.
Sentiment Analysis
Modern sentiment prediction systems don’t just look at words in isolation but build a representation of a sentence, based on its structure. A sentiment value can then be computed based on how words compose the meaning of longer phrases. Here, for example, I have charted the above-mentioned paragraph and analyzed by two distinct sentiment analyzers.

You might question the accuracy of sentiment predictions from systems like the Stanford NLP or the Valence Aware Dictionary and sEntiment Reasoner a.k.a. VADER. We had the same question…
We extracted thousands of sentences from modern novels and ran them through sentiment analyzers, which put them into 5 buckets: very-positive, positive, neutral, negative, and very negative. After manually removing sentences that were just too graphic, we stopped at about 200 sentences in each set.

Next, we asked randomly selected people to read and determine the attitude expressed in those 1000 sentences: if it were very positive, positive, neutral, negative, or very negative. 156 people tagged a total of 7470 sentences (on average a participant looked at about 50 sentences, containing sentences from each of the 5 sets).
91% of the responses matched exactly or were 1 off the sentiment analysis:
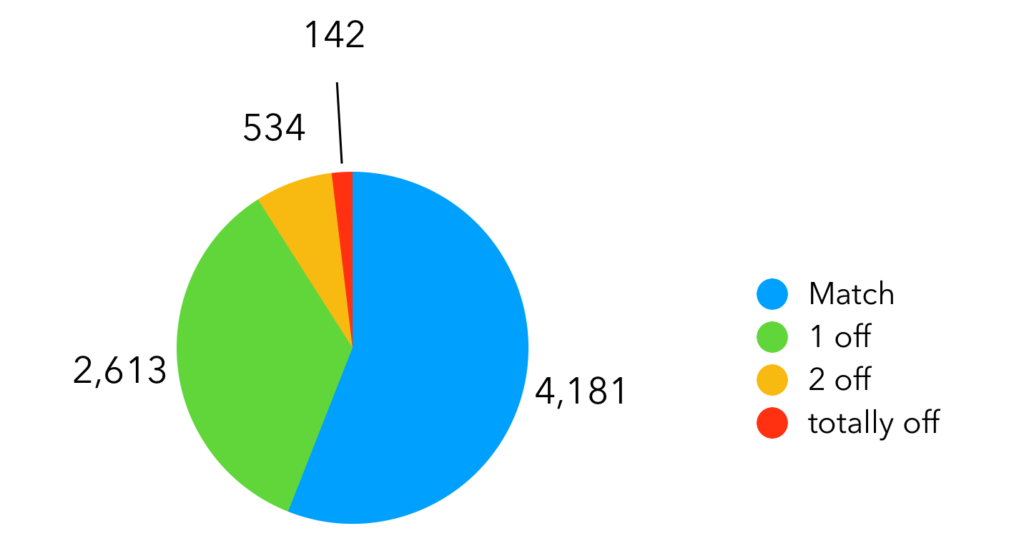
No matter how you look at it, predictions provided by sentiment analyzers are more often right than not.
Tone and Engagement in Text
Sometimes sentiment is not enough and off the shelf Tone in Text Analyzers can help to predict emotions and communication style in a text.
A Tone in Text Analyzer can be a very useful tool when verifying that a response, created to be displayed or uttered by a virtual assistant does not come across angry unless you meant it.
Readability Score
A readability score is a computer-calculated index, considering metrics like syllable count, sentence length and word difficulty, and can tell what level of education someone will need to be able to read a piece of text easily. The readability score might be even more important if the text will eventually be synthesized and a user has to listen to it.
We use different words and a different sentence length and structure in our written and spoken communication. Responses created for a virtual assistant need to keep that in mind as well. While it’s never unimportant to know your user base, it’s actually crucial to realize the education level required to comprehend the synthesized text, which a virtual assistant will then verbalize.
Summary
When compared to the Knowledge Navigator, Alexa and Google Home may look simplistic and not all that smart, but undeniably, the smart speaker is a very exciting new application platform. Interestingly, competing offerings are perceived as very similar and traditional differentiators like a delightful graphical user interface don’t seem to apply as much as before. In an otherwise un-differentiable experience, likability may become the ultimate differentiator. Not only what, but how a virtual assistant says it, will determine success.
Most of the tools and techniques mentioned here were created and are used to analyze user input or make sense of customer feedback. But don’t let that discourage you from using them to validate that a virtual assistant’s or chatbot’s response carries exclusively the intended attitude or sentiment.
I have only anecdotal evidence that “Please” and “Thanks” is said less often than before to smart speakers. Let’s make sure the skill or bot you are building responds kindly, considerately and empathically if warranted, and thereby deserves its user’s politeness. The number of “Thanks” your bot hears, might tell you, if you are on the right track.