To create a believable virtual agent or avatar, involves many dynamic tasks, one of which is to coordinate your character’s facial animation with a sound track. For a chat bot, a typical lip-sync process, may look something like this:
- Generate the voice track by synthesizing the text the bot needs to speak.
- Break down the voice track into phonemes, the smallest structural units of sound that distinguish meaning for a language.
- Animate the character’s face to synchronize with the phonemes in the dialogue.
Lip sync (short for lip synchronization), is a technical term for matching lip movements with sung or spoken vocals.
Voice speech is typically generated using a Text-to-Speech engine that resides on the device displaying the software agent or is part of web service. Either way, the input is always the (augmented) text and output a wave or mpeg3 sound file. Depending on the capabilities of the TTS-engine, the input text can be augmented with the intent to generate a more expressive voice sound. This can be achieved for instance, by simply inserting punctuation marks into the input text or by or using mark up, like defined in the Speech Synthesis Markup Language (SSML) or Emotional Markup Language (EmotionML).
Generally, pitch, volume, and speech (aka speech-rate) are the dynamic properties of the speech synthesis process. Examples for input text could look like this:
“Hello? Hello. Hello!”
.. or ..
SSML Markup
<?xml version="1.0"?> <speak version="1.0" xmlns="http://www.w3.org/2001/10/synthesis" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.w3.org/2001/10/synthesis http://www.w3.org/TR/speech-synthesis/synthesis.xsd" xml:lang="en-US"> That is a <emphasis> big </emphasis> car! That is a <emphasis level="strong"> huge </emphasis> bank account! </speak>
Phonemic Representation
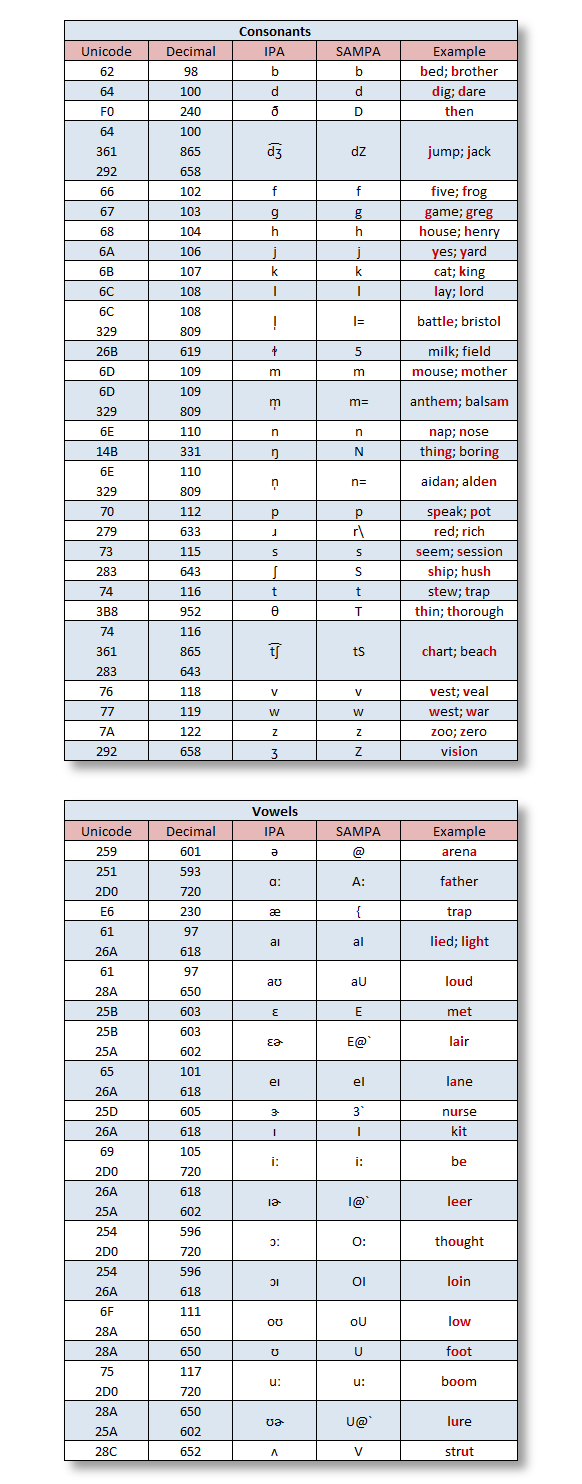
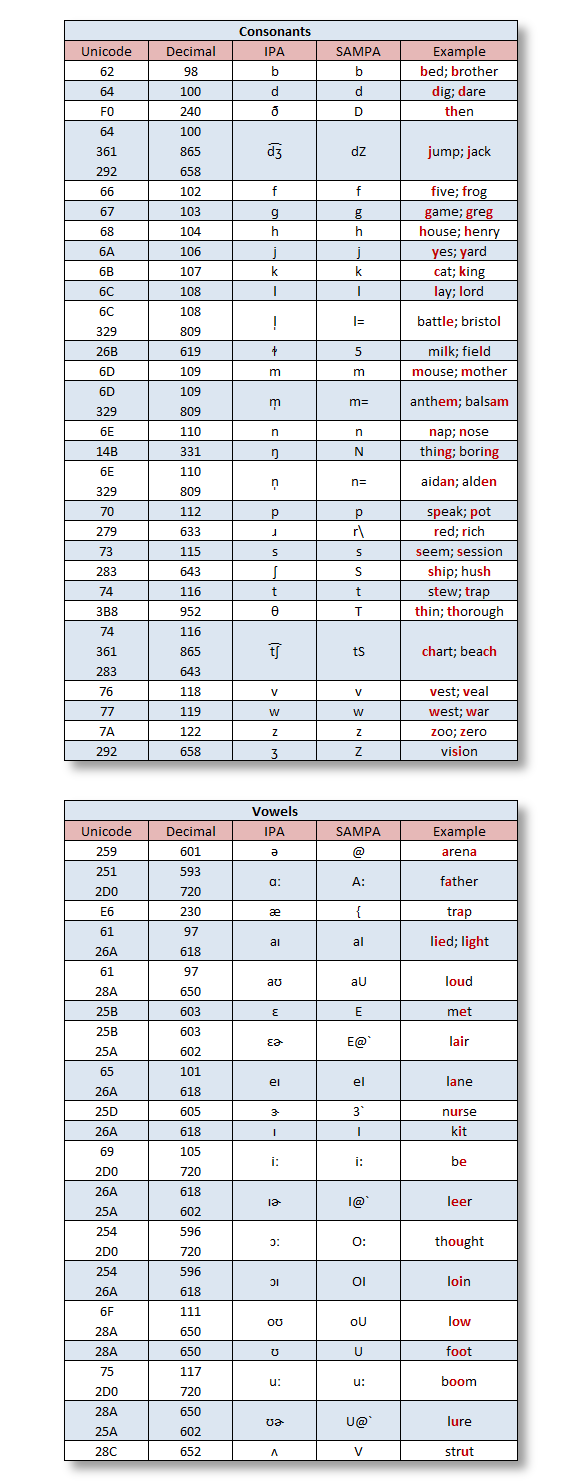
A phoneme is a basic unit of a language’s phonology. The table below (Source: LumenVox) shows the full set of IPA and X-SAMPA phonemes used by the LumenVox Text-To-Speech engine for American English.
Viseme
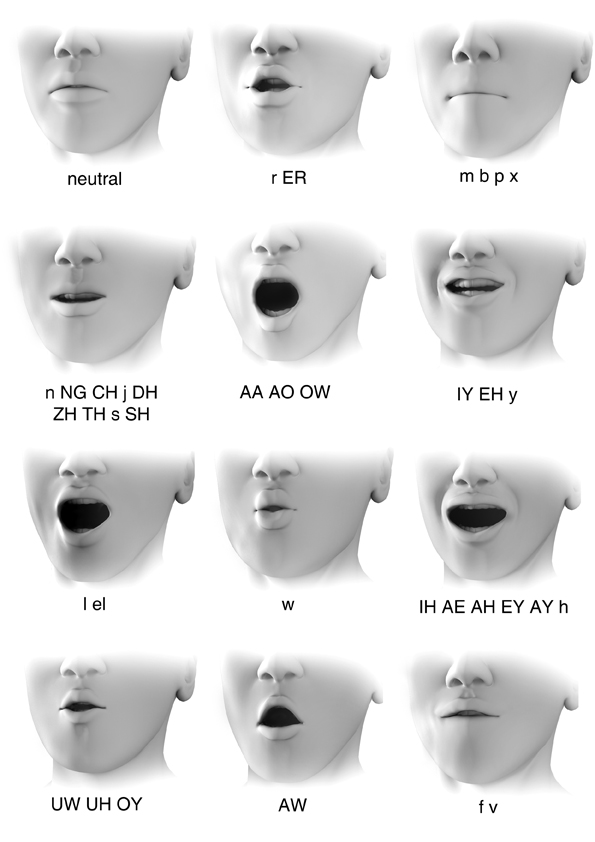
Where a phoneme is a basic acoustic unit of speech, a viseme is the basic visual unit of speech, representing a lip pose. Visemes and phonemes do not share a one-to-one correspondence, as several phonemes look the same on the face when produced.
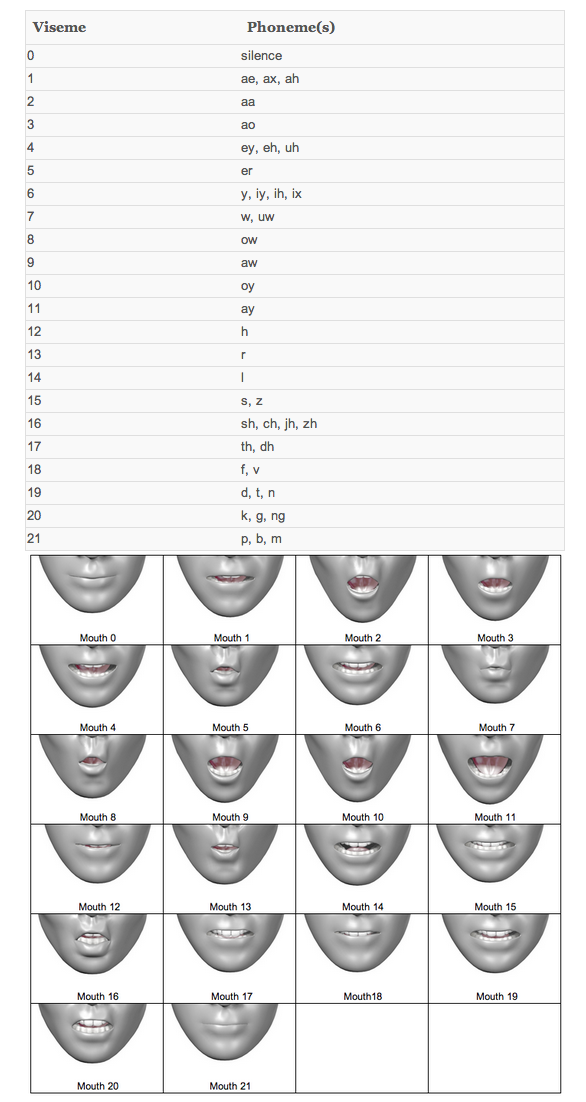
The table below shows a standard 22-Viseme model with phoneme mapping.
Viseme Model with 22 mouth shapes
The next table shows a simpler, 12 mouth position, viseme model, mapping all phonemes into a set of only 12 lip poses.
Viseme Model with 12 mouth shapes
TTS engines from different vendors provide different approaches to get to the voice sound file and the phoneme information. iSpeech for instance requires two web service calls with the same input text: one to request the voice sound file and another one to request the time-coded phoneme data.
A much more involved, but integrated solution can for instance be created with the Acapele TTS Engine, using its NSCAPI interface.
Acapela NSCAPI
When a text synthesis request is processed, this TTS Engine calls an event-handler (CallBackSpeechEvent), every time a new phoneme is generated.
Once the synthesis is complete (or in-between for streaming), another event-handler (CallBackSpeechData) is called, informing the client to pickup the voice sound file.
Here is data structure provided, with every phoneme change during synthesis:
NSC_EVENT_DATA_PhoSynch
typedef struct {
unsigned int uiSize; // Size of the structure
void *pUserData; // User pointer passed to the nscAddText function.
char cEngine_Phoneme[2*MAXCHAR_PHONEME+1]; //phoneme (up to 4 characters null-terminated string)
unsigned short uiIpa_Phoneme[MAX_IPA_PAR_PHO]; // IPA phoneme
unsigned int uiViseme; // Viseme
unsigned int uiDuration; // Phoneme duration in ms.
unsigned int uiByteCount; // Position in bytes in whole audio signal.
} NSC_EVENT_DATA_PhoSynch;
Like the NSC_EVENT_DATA_PhoSynch datastructure makes obvious, the Acapela NSCAPI event does not only provide the phoneme but also the viseme (in this case, for the 22 viseme lip-pose model)
Mapping this down to the 12 lip pose model however, can be done using this simple Mouth array:
22 to 12 Lip-Poses Mapping
const char * MOUTH[] = {
"silence\0",
"ae_ax_ah_aa_ao_er_ay\0",
"ae_ax_ah_aa_ao_er_ay\0",
"ae_ax_ah_aa_ao_er_ay\0",
"ey_eh_uh\0",
"ae_ax_ah_aa_ao_er_ay\0",
"aw_y_iy_ih_ix_h_k_g_n\0",
"w_uw\0",
"ow\0",
"aw_y_iy_ih_ix_h_k_g_n\0",
"oy\0",
"ae_ax_ah_aa_ao_er_ay\0",
"aw_y_iy_ih_ix_h_k_g_n\0",
"r\0",
"l\0",
"s_z_d_t_n\0",
"sh_ch_jh_zh\0",
"th_dh\0",
"f_v\0",
"s_z_d_t_n\0",
"aw_y_iy_ih_ix_h_k_g_n\0",
"p_m_b\0"};
.. and using something like this in the event-handler function:
22 to 12 Lip Poses Mapping
unsigned int viseme_dur = 100;
char viseme_doc[4000] = "\0";
char viseme_xml[4000] = "\0";
int CallBackSpeechEvent(unsigned int nEventID,
unsigned int cbEventDataSize,
PNSC_EVENT_DATA pEventData,
void *pAppInstanceData) {
switch(nEventID) {
..
case NSC_EVID_PHO_SYNCH_EXT:
{
// need to create something like this:
// <VISEME start="1">aw_y_iy_ih_ix_h_k_g_n</VISEME>
char s[80];
NSC_EVENT_DATA_PhoSynchExt *pEvent = (NSC_EVENT_DATA_PhoSynchExt *)pEventData;
unsigned int viseme = (unsigned int)pEvent->uiViseme;
unsigned int duration = (unsigned int)pEvent->uiDuration;
sprintf(s,"<VISEME start=\"%d\">%s</VISEME>\0", viseme_dur, MOUTH[viseme % 22]);
strcat(viseme_doc, s);
viseme_dur+=duration;
break;
}
case NSC_EVID_TEXT_DONE :
{
NSC_EVENT_DATA_TextDone *pEvent = (NSC_EVENT_DATA_TextDone *)pEventData;
// wrap the viseme xml to create a valid xml doc
char header[80];
sprintf(header,"<LIPSYNC duration=\"%d\">\0",viseme_dur);
viseme_xml[0] = '\0';
strcat(viseme_xml,header);
strcat(viseme_xml,viseme_doc);
strcat(viseme_xml,"</LIPSYNC>\0");
viseme_dur = 100;
viseme_doc[0] ='\0';
//
// converts, allocates, and returns a new buffer, containing the mp3 encoded data
//
int mp3_size =0;
unsigned char* mp3 = convert((short int*)(pcmBuffer), pcmOffset, &mp3_size);
free(pcmBuffer);
pcmBuffer=NULL;
//
// write mp3 data into file
//
fwrite(mp3,mp3_size,1,(FILE *)pAppInstanceData);
free(mp3);
mp3=NULL;
break;
}
}
return 0;
}
The event handler’s NSC_EVID_TEXT_DONE case already hints at the fact that the voice sound data is not in a useable format, i.e. the TTS engine usually creates pcm or wave sound files, which need to be converted and compressed, using an MP3 encoder.
Not only is MP3 widely supported and the resulting file size is much smaller, compared to the originally provided, pcm wave file, it also supports the containment of metadata.
ID3 is a metadata container that can be used in conjunction with the MP3 audio file format. It allows information such as the title, artist, album, track number, and other information about the file to be stored in the file itself. Adding the time-coded viseme data (here in form of an XML document) right into the mp3 voice sound file, make it easily available in a single web service call response.
PCM to MP3 w/ ID3 comment injection
//
// Converts a raw PCM buffer to MP3.
// Returns a unsigned char * to the new mp3 data,
// mp3_size is set to the mp3 buffer size.
// Also adds viseme_xml string into the mp3 id3 comment tag
//
unsigned char *convert(short int *buffer, int num_bytes, int* mp3_size) {
printf("PCM buffer size %d\n",num_bytes);
// number of samples in raw pcm audio
const int num_samples = num_bytes>>1;
// worst case buffer size for mp3 buffer
const int MP3_SIZE = 1.25 * num_samples + 7200;
//short int pcm_buffer[PCM_SIZE];
unsigned char* mp3_buffer= (unsigned char *) malloc(MP3_SIZE);
const lame_t lame = lame_init();
if ( lame == NULL ) {
printf("Unable to initialize MP3 encoder LAME\n");
return NULL;
}
lame_set_num_channels(lame,1);
lame_set_in_samplerate(lame, 22050);
lame_set_out_samplerate(lame, 22050);
lame_set_brate(lame,128);
lame_set_mode(lame,MONO);
lame_set_quality(lame,2);
lame_set_bWriteVbrTag(lame, 0);
lame_set_VBR(lame, vbr_default);
id3tag_set_comment(lame, viseme_xml);
if ( lame_init_params(lame) < 0 ) {
printf("Unable to initialize MP3 parameters\n");
return NULL;
}
int size;
size = lame_encode_buffer(lame, buffer, buffer, num_samples, mp3_buffer, MP3_SIZE);
size+= lame_encode_flush(lame, mp3_buffer+size, MP3_SIZE);
lame_close(lame);
*mp3_size = size;
return (unsigned char *)realloc(mp3_buffer,size);
}
Lipsync Xml Document
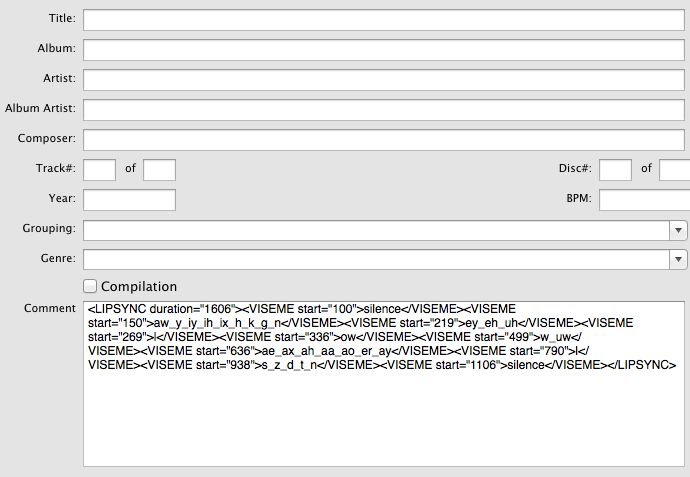
<LIPSYNC duration="1606"> <VISEME start="100">silence</VISEME> <VISEME start="150">aw_y_iy_ih_ix_h_k_g_n</VISEME> <VISEME start="219">ey_eh_uh</VISEME> <VISEME start="269">l</VISEME> <VISEME start="336">ow</VISEME> <VISEME start="499">w_uw</VISEME> <VISEME start="636">ae_ax_ah_aa_ao_er_ay</VISEME> <VISEME start="790">l</VISEME> <VISEME start="938">s_z_d_t_n</VISEME> <VISEME start="1106">silence</VISEME> </LIPSYNC>
The convert function above, requires the LAME opensource mp3 encoder to be installed. LAME is a high quality MPEG Audio Layer III (MP3) encoder licensed under the LGPL. Installing LAME on RedHat 6 for instance could be done like so:
mkdir ~/tmp cd ~/tmp wget http://packages.sw.be/rpmforge-release/rpmforge-release-0.5.2-2.el6.rf.x86_64.rpm sudo rpm --import http://apt.sw.be/RPM-GPG-KEY.dag.txt sudo rpm -i rpmforge-release-0.5.2-2.el6.rf.*.rpm sudo yum install lame lame-devel
Here is a sample mp3 file, containing the Lipsync Xml document in the MP3-ID3 comment tag:
Using an MP3 Tag-Editor like Tagger, makes the comment tag visible: