
About 37%, or in numbers, 95 million U.S. adults have smart speakers in their homes. Half of them are daily active users. However, in the last two years, user growth has only been at 4%.
(Smart Speaker Consumer Adoption Report Mach 2022)
About 70% of surveyed businesses stated that voice-enabled digital assistant technology is critical to their digital transformation plan.
However, only 30% are already executing their plan, while almost 50% are still planning.
(Voice Reports 2021 Voice Business Integration Survey)
With those numbers in mind, let’s focus on building voice-enabled assistant technology better and faster. Creating a voice user interface, maybe an Alexa Skill, is not as easy as it might first appear. Processing information into something a user would listen to, requires more and deeper domain knowledge than expected.
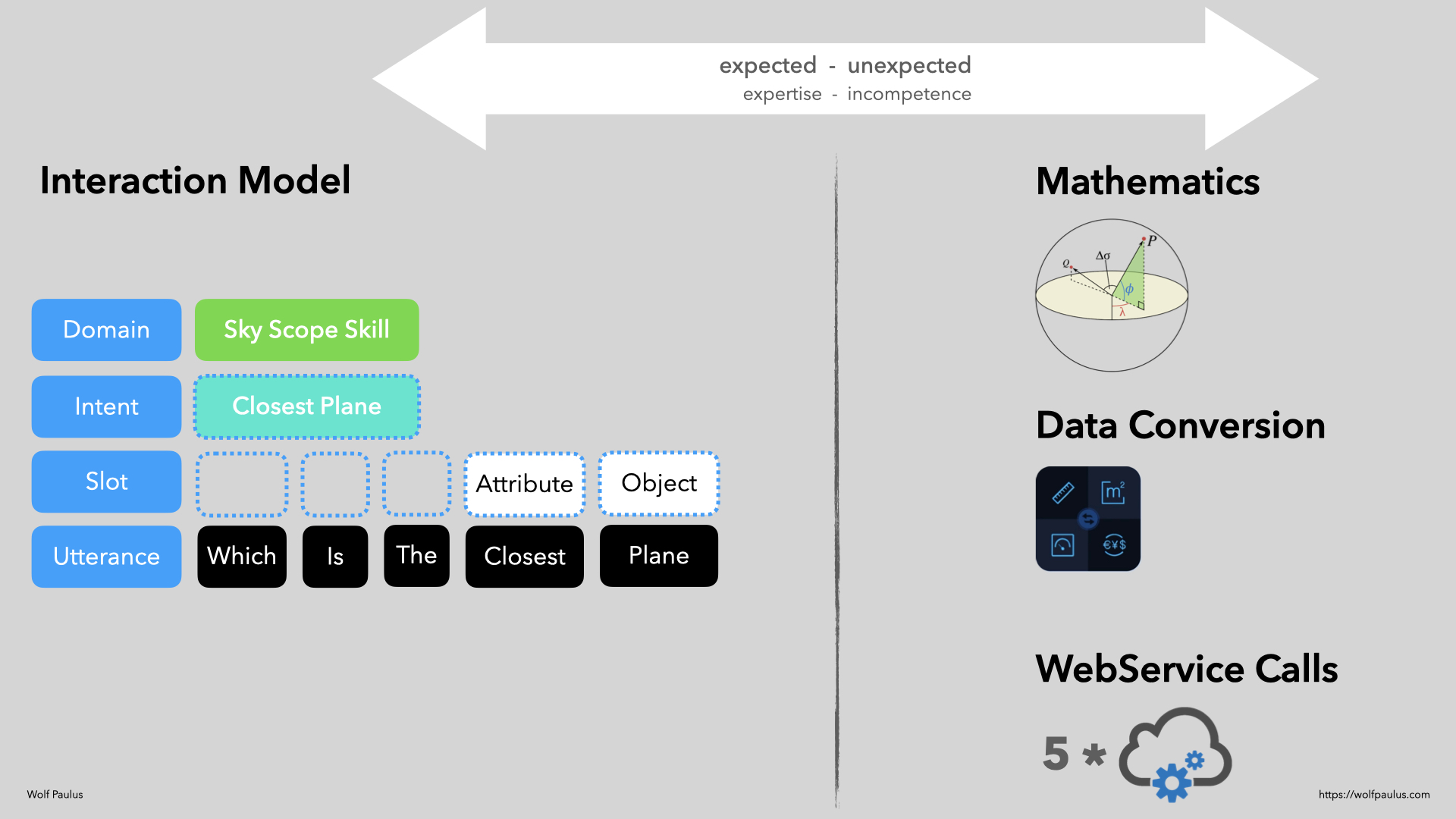
Maybe there is something to be learned from Web Development?
Looking for instance at how much the Yahoo homepage has changed in 25 years, it’s probably expected that the process and tools have changed too. Originally, server-side programming was used, then Server-side scripting, and more recently, client-side scripting became the dominant technology. Most importantly, a strict separation of concerns was established: content, style, and logic are detached.

While Amazon innovated remarkably on Echo Devices, I’m afraid that the way 3rd party Alexa Skills are built, has not changed all that much. Struggling with too many API calls and requiring deep domain knowledge is hinting at an insufficient separation of concerns and that APIs were not designed with conversational user interfaces in mind.
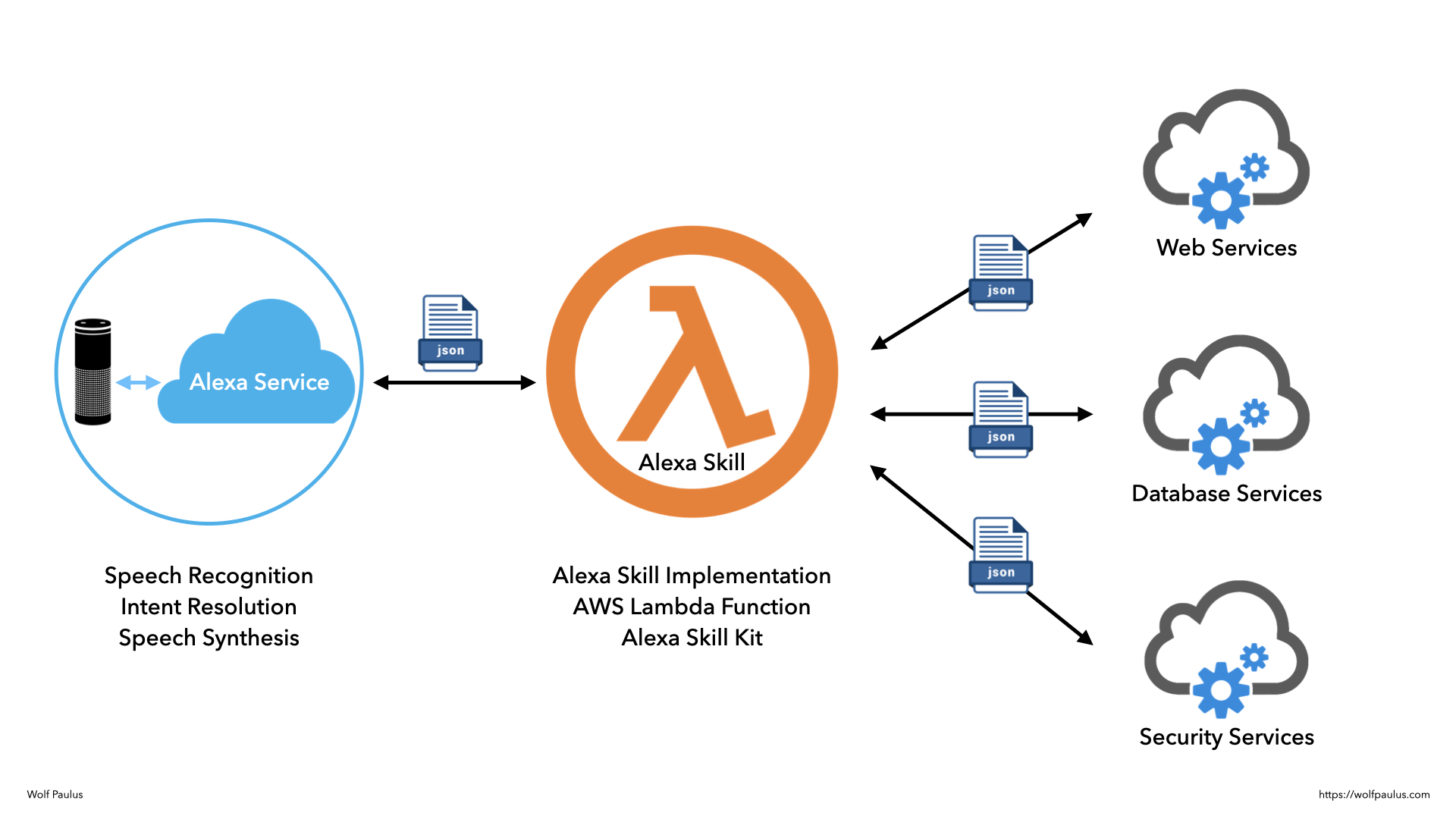
So how could we build voice-enabled assistant technology better and faster?
We have to get away from a “WebMaster of Voice” approach and instead promote the separation of concerns for voice apps, for instance by separating into Content, Style (emphasis, emotion, etc.), and Dialog-Management.
We need to design APIs with CUI in mind and put “CUI consumable content” into every API response.
This was an interesting read, Wolf. Hopefully, we will see this implemented by amazon and google in the future!