
I’m still remembering it well, the first piece of software I wrote when I came to the US was a de-skewing algorithm. Deskewing an image helps a lot, if you want to do OCR, OMR, barcode detect, or just improve the readability of scanned images.
At the time, I was working for a small software company, developing TeleForm, an application that reads data from paper forms and stores that data in previously created databases. The Cardiff TeleForm product was later re-branded Verity-TeleForm for a brief period in 2004 and 2005 when Verity Inc. acquired Cardiff Software. In 2005, when Autonomy acquired Verity, the Cardiff brand was reintroduced as Autonomy Cardiff (http://www.cardiff.com); more recently, Autonomy was acquired by HP.
Now most of the data entry or origination happens on the Web, where most of the forms processing has been moved to as well, i.e. OCR hasn’t been in vogue for quite a while. However, the popularity of smartphones, combined with built-in high-quality cameras has created a new category of mobile applications, benefiting greatly from OCR. Take Word-Lens (http://questvisual.com) as an example: an augmented reality translation application that tries to find out what the letters are in an image and then looks in a dictionary, to eventually draws the words back on the screen in translation.
On Device or In The Cloud ?
Before deciding on an OCR library, one needs to decide, where the OCR process should take place: on the Smartphone or in the Cloud. Each approach has its advantages.
On device OCR can be performed without requiring an Internet connection and instead of sending a photo, which can potentially be huge (many phones have 8 or 12 Mega-Pixel cameras now), the text is recognized by an on-board OCR-engine.
However, OCR-libraries tend to be large, i.e. the mobile application will be of considerable size. Depending on the amount of text that needs to be recognized and the available data transfer speed, a cloud-service may provide the result faster. A cloud-service can be updated more easily but individually optimizing (training) an OCR engine may work better when done locally on the device.
Which OCR Library to choose ?
- Wikipedia has a “non-exhaustive” but still very broad comparison of optical character recognition software here: http://en.wikipedia.org/wiki/ List_of_optical_character_recognition_software
- A comparison of some of the more popular OCR-Engines can be found here: http://www.freewaregenius.com/2011/11/01/how-to-extract-text-from-images-a- comparison-of-free-ocr-tools/
- Linux OCR software comparison with a strong focus on accuracy: http://www.splitbrain.org/blog/2010-06/15-linux_ocr_software_comparison
After taking a closer look at the all comparisons, Tesseract stands out. It provides good accuracy, it’s open-source and Apache-Licensed, and has broad language support. It was created by HP and is now developed by Google.
Also, since Tesseract is open source and Apache- Licensed, we can take the source and port it to the Android platform, or put it on a Web-server to run our very own Cloud-service.
1. Tesseract
The Tesseract OCR engine was developed at Hewlett Packard Labs and is currently sponsored by Google. It was among the top three OCR engines in terms of character accuracy in 1995. http://code.google.com/p/tesseract-ocr/
1.1. Running Tesseract locally on a Mac
Like with so make other Unix and Linux tools, Homebrew (http://mxcl.github.com/homebrew/) is the easiest and most flexible way to install the UNIX tools Apple didn’t include with OS X. Once Homebrew is installed (https://github.com/mxcl/homebrew/wiki/installation), Tesseract can be installed on OS X as easy as:
$ brew install tesseract
Once installed,
$ brew info tesseract will return something like this:
tesseract 3.00
http://code.google.com/p/tesseract-ocr/
Depends on: libtiff
/usr/local/Cellar/tesseract/3.00 (316 files, 11M)
Tesseract is an OCR (Optical Character Recognition) engine.
The easiest way to use it is to convert the source to a Grayscale tiff:
`convert source.png -type Grayscale terre_input.tif`
then run tesseract:
`tesseract terre_input.tif output`
http://github.com/mxcl/homebrew/commits/master/Library/Formula/tesseract.rb
Tesseract doesn’t come with a GUI and instead runs from a command-line interface. To OCR a TIFF-encoded image located on your desktop, you would do something like this:
$ tesseract ~/Desktop/cox.tiff ~/Desktop/cox
Using the image below, Tesseract wrote with perfect accuracy the resulting text into
~/Desktop/cox.txt
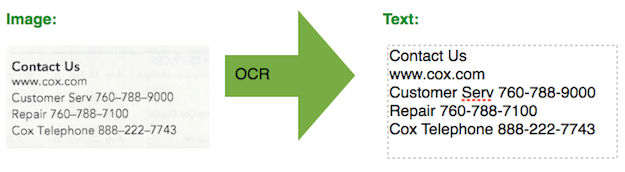
There are at least two projects, providing a GUI-front-end for Tesseract on OS X
- TesseractGUI, a native OSX client: http://download.dv8.ro/files/TesseractGUI/
- VietOCR, a Java Client: http://vietocr.sourceforge.net/
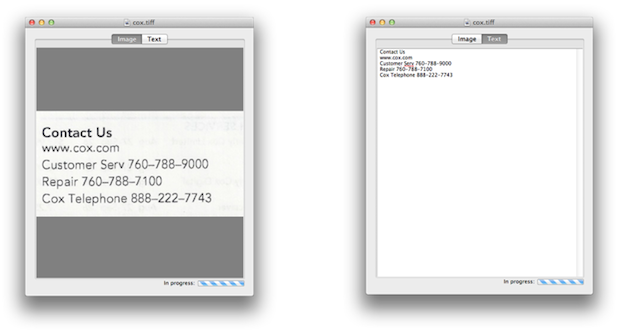
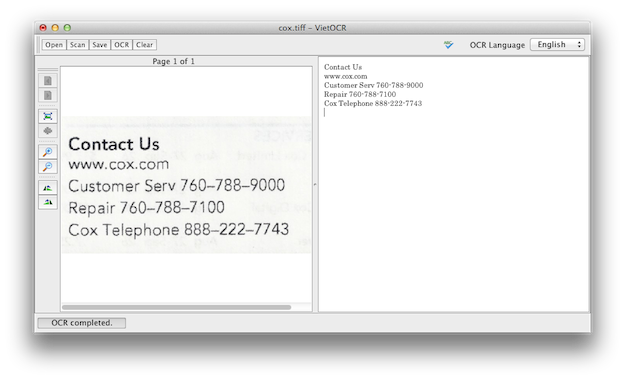
1.2. Running Tesseract as a Cloud-Service on a Linux Server
One of the fastest and easiest ways to deploy Tesseract as a Web-service, uses Tornado (http://www.tornadoweb.org/), an open source (Apache Licensed) Python non-blocking web server. Since Tesseract accepts TIFF encoded images but our Cloud-Service should rather work with the more popular JPEG image format, we also need to deploy the free Python Imaging Library (http://www.pythonware.com/products/pil/), license terms are here: http://www.pythonware.com/products/pil/license.htm
The deployment on Ubuntu 11.10 64-bit server looks something like this:
sudo apt-get install python-tornado sudo apt-get install python-imaging sudo apt-get install tesseract-ocr
1.2.1. The HTTP Server-Script for port 8080
#!/usr/bin/env python
import tornado.httpserver
import tornado.ioloop
import tornado.web
import pprint
import Image
from tesseract import image_to_string
import StringIO
import os.path
import uuid
class MainHandler(tornado.web.RequestHandler):
def get(self):
self.write('</pre>
<form action="/" method="post" enctype="multipart/form-data">' '
<input type="file" name="the_file" />' '
<input type="submit" value="Submit" />' '</form>
<pre class="prettyprint">')
def post(self):
self.set_header("Content-Type", "text/html")
self.write("") # create a unique ID file
tempname = str(uuid.uuid4()) + ".jpg"
myimg = Image.open(StringIO.StringIO(self.request.files.items()[0][1][0 ['body']))
myfilename = os.path.join(os.path.dirname(__file__),"static",tempname);
# save image to file as JPEG
myimg.save(myfilename)
# do OCR, print result
self.write(image_to_string(myimg))
self.write("")
settings = {
"static_path": os.path.join(os.path.dirname(__file__), "static"),
}
application = tornado.web.Application([
(r"/", MainHandler),
], **settings)
if __name__ == "__main__":
http_server = tornado.httpserver.HTTPServer(application)
http_server.listen(8080)
tornado.ioloop.IOLoop.instance().start()
The Server receives a JPEG image file and stores it locally in the ./static directory, before calling image_to_string, which is defined in the Python script below:
1.2.2. image_to_string function implementation
#!/usr/bin/env python
tesseract_cmd = 'tesseract'
import Image
import StringIO
import subprocess
import sys
import os
__all__ = ['image_to_string']
def run_tesseract(input_filename, output_filename_base, lang=None, boxes=False):
'''
runs the command:
`tesseract_cmd` `input_filename` `output_filename_base`
returns the exit status of tesseract, as well as tesseract's stderr output
'''
command = [tesseract_cmd, input_filename, output_filename_base]
if lang is not None:
command += ['-l', lang]
if boxes:
command += ['batch.nochop', 'makebox']
proc = subprocess.Popen(command,
stderr=subprocess.PIPE)
return (proc.wait(), proc.stderr.read())
def cleanup(filename):
''' tries to remove the given filename. Ignores non-existent files '''
try:
os.remove(filename)
except OSError:
pass
def get_errors(error_string):
'''
returns all lines in the error_string that start with the string "error"
'''
lines = error_string.splitlines()
error_lines = tuple(line for line in lines if line.find('Error') >= 0)
if len(error_lines) > 0:
return '\n'.join(error_lines)
else:
return error_string.strip()
def tempnam():
''' returns a temporary file-name '''
# prevent os.tmpname from printing an error...
stderr = sys.stderr
try:
sys.stderr = StringIO.StringIO()
return os.tempnam(None, 'tess_')
finally:
sys.stderr = stderr
class TesseractError(Exception):
def __init__(self, status, message):
self.status = status
self.message = message
self.args = (status, message)
def image_to_string(image, lang=None, boxes=False):
'''
Runs tesseract on the specified image. First, the image is written to disk,
and then the tesseract command is run on the image. Resseract's result is
read, and the temporary files are erased.
'''
input_file_name = '%s.bmp' % tempnam()
output_file_name_base = tempnam()
if not boxes:
output_file_name = '%s.txt' % output_file_name_base
else:
output_file_name = '%s.box' % output_file_name_base
try:
image.save(input_file_name)
status, error_string = run_tesseract(input_file_name,
output_file_name_base,
lang=lang,
boxes=boxes)
if status:
errors = get_errors(error_string)
raise TesseractError(status, errors)
f = file(output_file_name)
try:
return f.read().strip()
finally:
f.close()
finally:
cleanup(input_file_name)
cleanup(output_file_name)
if __name__ == '__main__':
if len(sys.argv) == 2:
filename = sys.argv[1]
try:
image = Image.open(filename)
except IOError:
sys.stderr.write('ERROR: Could not open file "%s"\n' % filename)
exit(1)
print image_to_string(image)
elif len(sys.argv) == 4 and sys.argv[1] == '-l':
lang = sys.argv[2]
filename = sys.argv[3]
try:
image = Image.open(filename)
except IOError:
sys.stderr.write('ERROR: Could not open file "%s"\n' % filename)
exit(1)
print image_to_string(image, lang=lang)
else:
sys.stderr.write('Usage: python tesseract.py [-l language] input_file\n')
exit(2)
1.2.3. The Service deploy/start Script
description "OCR WebService" start on runlevel [2345] stop on runlevel [!2345] pre-start script mkdir /tmp/ocr mkdir /tmp/ocr/static cp /usr/share/ocr/*.py /tmp/ocr end script exec /tmp/ocr/tesserver.py
After the service has been started, it can be accessed through a Web browser like shown here: http://proton.techcasita.com:8080 I’m currently running tesseract 3.01 on Ubuntu Linux 11.10 64-bit, please be gentle, it runs on an Intel Atom CPU 330 @ 1.60GHz, 4 cores (typically found in Netbooks)
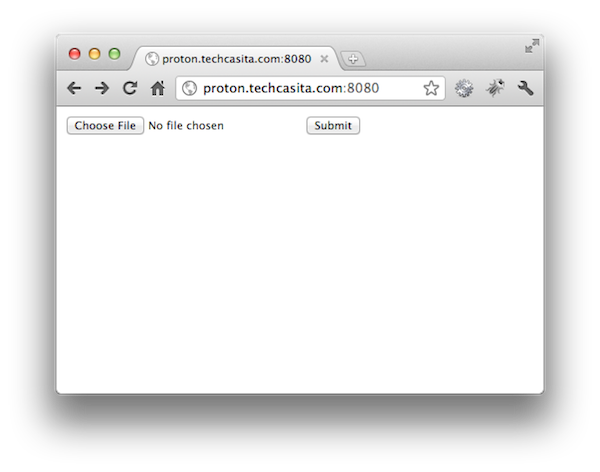
The HTML encoded result looks something like this:
<html><body>Contact Us www. cox.com Customer Serv 760-788-9000 Repair 76O—788~71O0 Cox Telephone 888-222-7743</body></html>
1.3 Accessing the Tesseract Cloud-Service from Android
The OCRTaskActivity below utilizes Android’s built-in AsyncTask as well as Apache Software Foundation’s HttpComponent library HttpClient4.1.2, available here: http://hc.apache.org/httpcomponents-client-ga/index.html OCRTaskActivity expects the image to be passed in as the Intent Extra “ByteArray” of type ByteArray. The OCR result is returned to the calling Activity as OCR_TEXT, like shown here:
setResult(Activity.RESULT_OK, getIntent().putExtra("OCR_TEXT", result));
import android.app.Activity;
import android.graphics.BitmapFactory;
import android.os.AsyncTask;
import android.os.Bundle;
import android.util.Log;
import android.view.View;
import android.widget.ImageView;
import android.widget.ProgressBar;
import org.apache.http.HttpResponse;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.entity.mime.HttpMultipartMode;
import org.apache.http.entity.mime.MultipartEntity;
import org.apache.http.entity.mime.content.ByteArrayBody;
import org.apache.http.entity.mime.content.StringBody;
import org.apache.http.impl.client.DefaultHttpClient;
import java.io.BufferedReader;
import java.io.InputStreamReader;
public class OCRTaskActivity extends Activity {
private static String LOG_TAG = OCRAsyncTaskActivity.class.getSimpleName();
private static String[] URL_STRINGS = {"http://proton.techcasita.com:8080"};
private byte[] mBA;
private ProgressBar mProgressBar;
@Override
public void onCreate(final Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.ocr);
mBA = getIntent().getExtras().getByteArray("ByteArray");
ImageView iv = (ImageView) findViewById(R.id.ImageView);
iv.setImageBitmap(BitmapFactory.decodeByteArray(mBA, 0, mBA.length));
mProgressBar = (ProgressBar) findViewById(R.id.progressBar);
OCRTask task = new OCRTask();
task.execute(URL_STRINGS);
}
private class OCRTask extends AsyncTask {
@Override
protected String doInBackground(final String... urls) {
String response = "";
for (String url : urls) {
try {
response = executeMultipartPost(url, mBA);
Log.v(LOG_TAG, "Response:" + response);
break;
} catch (Throwable ex) {
Log.e(LOG_TAG, "error: " + ex.getMessage());
}
}
return response;
}
@Override
protected void onPostExecute(final String result) {
mProgressBar.setVisibility(View.GONE);
setResult(Activity.RESULT_OK, getIntent().putExtra("OCR_TEXT", result));
finish();
}
}
private String executeMultipartPost(final String stringUrl, final byte[] bm) throws Exception {
HttpClient httpClient = new DefaultHttpClient();
HttpPost postRequest = new HttpPost(stringUrl);
ByteArrayBody bab = new ByteArrayBody(bm, "the_image.jpg");
MultipartEntity reqEntity = new MultipartEntity(HttpMultipartMode.BROWSER_COMPATIBLE);
reqEntity.addPart("uploaded", bab);
reqEntity.addPart("name", new StringBody("the_file"));
postRequest.setEntity(reqEntity);
HttpResponse response = httpClient.execute(postRequest);
BufferedReader reader = new BufferedReader(new InputStreamReader(response.getEntity().getContent(), "UTF-8"));
String sResponse;
StringBuilder s = new StringBuilder();
while ((sResponse = reader.readLine()) != null) {
s = s.append(sResponse).append('\n');
}
int i = s.indexOf("body");
int j = s.lastIndexOf("body");
return s.substring(i + 5, j - 2);
}
}
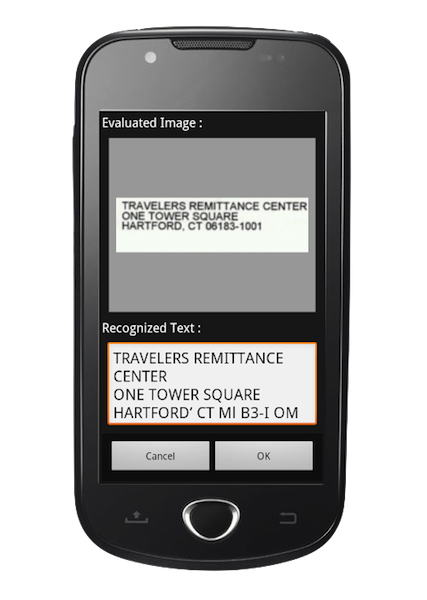
1.4. Building a Tesseract native Android Library to be bundled with an Android App
This approach allow an Android application to perform OCR even without a network connection. I.e. the OCR engine is on-board. There are currently two source-bases to start from, the original Tesseract project here:
- Tesseract Tools for Android is a set of Android APIs and build files for the Tesseract OCR and Leptonica image processing libraries:
svn checkout http://tesseract-android-tools.googlecode.com/svn/trunk/ tesseract-android-tools
- A fork of Tesseract Tools for Android (tesseract-android-tools) that adds some additional functions:
git clone git://github.com/rmtheis/tess-two.git
… I went with option 2.
1.4.1. Building the native lib
Each project can be build with the same build steps (see below) and neither works with Android’s NDK r7. However, going back to NDK r6b solved that problem. Here are the build steps. It takes a little while, even on a fast machine.
cd <project-directory>/tess-two
export TESSERACT_PATH=${PWD}/external/tesseract-3.01
export LEPTONICA_PATH=${PWD}/external/leptonica-1.68
export LIBJPEG_PATH=${PWD}/external/libjpeg
ndk-build
android update project --path .
ant release
The build-steps create the native libraries in the libs/armabi and libs/armabi-v7a directories.
The tess-two project can now be included as a library-project into an Android project and with the JNI layer in place, calling into the native OCR library now looks something like this:
1.4.2. Developing a simple Android App with built-in OCR capabilities
... TessBaseAPI baseApi = new TessBaseAPI(); baseApi.init(DATA_PATH, LANG); baseApi.setImage(bitmap); String recognizedText = baseApi.getUTF8Text(); baseApi.end(); ...
1.4.2.1. Libraries / TrainedData / App Size
The native libraries are about 3 MBytes in size. Additionally, a language and font depending training resource files is needed.
The eng.traineddata file (e.g. available with the desktop version of Tesseract) is placed into the main android’s assers/tessdata folder and deployed with the application, adding another 2 MBytes to the app. However, due to compression, the actual downloadable Android application is “only” about 4.1 MBytes.
During the first start of the application, the eng.traineddata resource file is copied to the phone’s SDCard.
The ocr() method for the sample app may look something like this:
protected void ocr() {
BitmapFactory.Options options = new BitmapFactory.Options();
options.inSampleSize = 2;
Bitmap bitmap = BitmapFactory.decodeFile(IMAGE_PATH, options);
try {
ExifInterface exif = new ExifInterface(IMAGE_PATH);
int exifOrientation = exif.getAttributeInt(ExifInterface.TAG_ORIENTATION, ExifInterface.ORIENTATION_NORMAL);
Log.v(LOG_TAG, "Orient: " + exifOrientation);
int rotate = 0;
switch (exifOrientation) {
case ExifInterface.ORIENTATION_ROTATE_90:
rotate = 90;
break;
case ExifInterface.ORIENTATION_ROTATE_180:
rotate = 180;
break;
case ExifInterface.ORIENTATION_ROTATE_270:
rotate = 270;
break;
}
Log.v(LOG_TAG, "Rotation: " + rotate);
if (rotate != 0) {
// Getting width & height of the given image.
int w = bitmap.getWidth();
int h = bitmap.getHeight();
// Setting pre rotate
Matrix mtx = new Matrix();
mtx.preRotate(rotate);
// Rotating Bitmap
bitmap = Bitmap.createBitmap(bitmap, 0, 0, w, h, mtx, false);
// tesseract req. ARGB_8888
bitmap = bitmap.copy(Bitmap.Config.ARGB_8888, true);
}
} catch (IOException e) {
Log.e(LOG_TAG, "Rotate or coversion failed: " + e.toString());
}
ImageView iv = (ImageView) findViewById(R.id.image);
iv.setImageBitmap(bitmap);
iv.setVisibility(View.VISIBLE);
Log.v(LOG_TAG, "Before baseApi");
TessBaseAPI baseApi = new TessBaseAPI();
baseApi.setDebug(true);
baseApi.init(DATA_PATH, LANG);
baseApi.setImage(bitmap);
String recognizedText = baseApi.getUTF8Text();
baseApi.end();
Log.v(LOG_TAG, "OCR Result: " + recognizedText);
// clean up and show
if (LANG.equalsIgnoreCase("eng")) {
recognizedText = recognizedText.replaceAll("[^a-zA-Z0-9]+", " ");
}
if (recognizedText.length() != 0) {
((TextView) findViewById(R.id.field)).setText(recognizedText.trim());
}
}
OCR on Android
The popularity of smartphones, combined with built-in high-quality cameras has created a new category of mobile applications, benefiting greatly from OCR.
OCR is very mature technology with a broad range of available libraries to chose from. There are Apache and BSD licensed, fast and accurate solutions available from the open-source community, I have taken a closer look at Tesseract, which is developed by HP and Google.
Tesseract can be used to build a Desktop application, a CloudService, and even baked into a mobile Android application, performing on-board OCR. All three variation of OCR with the Tesseract library have been demonstrated above.
Focussing on mobile applications, however, it became very clear that even on phones with a 5MP camera, the accuracy of the results still vary greatly, depending on lighting conditions, font, and font-sizes, as well as surrounding artifact.
Just like with the TeleForm application, even the best OCR engines perform purely, if the input-image has not been prepared correctly. To make OCR work on a mobile device, no matter if the OCR will eventually be run onboard or in the cloud, much development time needs to be spend to train the engine – but even more importantly, to select and prepare the image areas that will be provided as input to the OCR engine – it’s going to be all about the pre-processing.

thanks .. amazing work …but a little bit limited
hai nice tutorial, but how could intergrated native using cmakelist? i tried to using include base api on c++ JNI, thanks
java.net.UnknownHostException: Unable to resolve host “proton.techcasita.com”: No address associated with hostname